Textual processing is simple and effective on a low level of sophistication, and an uphill battle from then on. Why is it that so many ambitious projects -- grammar checking, text-to-speech and speech-to-text conversion, parsing, and machine translation -- usually bottom out with no other result than a list of complaints? FOX and TreeCad are two small, PC-based programs written in Icon and using that language's powerful prototyping capabilities [1]. FOX is an experimental parser; TreeCad is a utility for designing and manipulating syntax trees. On a very small scale, the two programs illustrate the potential and the limits of computational textual analysis.
Texts and strings
On the most primitive level of analysis, a text is just a stream of characters with line feeds at certain intervals. From a simple word-processing point of view, a text divides into words, sentences, paragraphs, and chapters. Since most of these elements have their own sets of dedicated delimiters, it is a more or less routine exercise to write a program that "tags" or "tokenizes" a text according to these categories. Most programming languages support long strings and an assortment of string analysis functions allowing flexible searches, substitutions, rearrangements, and so on.
From the point of view of natural language analysis, this does not get us very far. Although the computer can easily identify a sentence, it does not recognize it for the essential expression of linguistic activity that it is, the unit in which we can cast judgments, descriptions, statements, questions, and commands. To get a grasp on what a [End of p. 101] sentence really is, the computer must be taught that it "predicates" something; that it has a subject, complements, and adjuncts; that it coordinates and subordinates its clauses; and that it can do so in a highly recursive manner ("I know you know that the dog that chased the cat that caught the rat that ate the cheese belongs to my sister's husband's niece"). These functional and structural properties of sentences are aspects which directly affect understanding. When readers complain that they do not understand, they can usually point out what is wrong, perhaps a "dangling" construction without a subject, an ambiguous phrase, or an unassignable modifier.
From treestrings to trees
Most of the structural and functional properties of sentences can be made explicit by parsing. Parsing a sentence like (1) is an elementary exercise for any student of linguistics:
(1) Mary saw John.
Some people intuitively work top down, beginning by dividing the sentence into its two major constituents, Mary + saw John, a noun phrase (NP) and a verb phrase (VP). The VP is then split into a verb (V) and another NP. Others go bottom up, first categorising the individual words as nouns or verbs, then combining these to make up the larger phrases. Both strategies usually lead to a tree diagram. Trees are ideally suited to represent hierarchical structures, but they are difficult to draw, cumbersome to print, and they do not edit gracefully. In computational terms, given a high-level language like Icon, the data structure underlying a tree is usually based on strings, lists, or user-defined records [2]. In order to exploit the string scanning functions in Icon, FOX and TreeCad make use of "treestrings", a string formalization closely related to (indeed, easily transformable into) what linguists call "labelled bracketing", a notation in which structural relationships are indicated by angular brackets, and each opening bracket is labelled by a subscripted category tag (NP, VP, etc.). Similarly, the parsing of (1) sketched above can be cast in the following "treestring" format: [End of p. 102]
(2) (S,(NP,Mary),(VP,(V,saw),(NP,John)))
The conventions here are simple: each nonterminal category is any label after an opening bracket (i.e., S, NP, VP, V, NP), and any item preceded by a comma (Mary, saw, John) is a terminal item.
However, even though (2) may be agreeable to a computer (and possibly LISP programmers), it is already difficult to grasp by ordinary human users. Obviously, to make syntactic structure explicit to human users, a procedure is needed to transform "treestrings" into proper tree representations. Depending on the type of representation aimed at - syntax trees can be displayed vertically or horizontally, grow upwards or downwards - this can be quite a nontrivial exercise. Since FOX and TreeCad work in text mode only, they use a non-proportional typeface and the line-drawing characters of the IBM/ASCII extended character set.
A parsing FOX
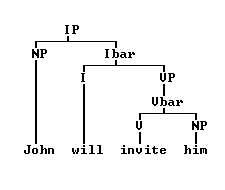
Because parsing is such a basic requirement in natural language analysis, the academic industry has produced an immense number of parsers and parsing strategies [3]. FOX, a "Frame-oriented X-bar Parser", uses an eclectic mix of strategies - a combined bottom-up and top-down approach, a certain amount of "look-ahead", and several passes over already-processed structures. The word "frame" in its acronym goes back to the frame concept of Artificial Intelligence research [4], indicating that FOX aims at mimicking the cognitive activities of a human parser, while "X-bar" refers to the set of canonical structures postulated in Government and Binding (GB) Theory [5]. Following the conventions of GB Theory, FOX attempts to work out a sentence's surface structure while preserving its underlying deep structure. Briefly, given a sentence like (1), FOX begins by looking up the words in a "lexicon" text file. From the lexicon, FOX learns that "John" and "Mary" are nouns (to be expanded into NPs) and that "saw" is the past tense of a transitive verb requiring a subject and an object. Acting on such "subcategorization frames", FOX builds a sequence of initially unconnected and incomplete trees. FOX then passes several times over the sequence, building additional structures as needed, reconstructing deep structure, and unifying unsaturated [End of p. 103] nodes. If all goes well, the outcome is a single, fully saturated tree as shown in (3). Due to the parser's X-bar orientation, category labels and structural properties deviate slightly from the analysis suggested in (2).
(3)
The representation in (3) encapsulates the functional properties of the sentence; for instance, a clause corresponds to an IP ("inflectional phrase"), its subject is an "IP-specifier" (that is, an immediate left branch of IP), an object is an immediate NP complement of a verb, and so on.
Of course, "Mary saw John" is a trivial example, and most sentences in natural language cannot be expected to work out quite so smoothly. However, for a program consisting of 1,000 lines only, about half of which are concerned with general housekeeping and tree display routines, FOX makes some creditable efforts. For example, it manages a nasty item like "What did John's sister's niece promise that she would do?", whose intricate X-bar representation can keep a human parser busy for some time. On the other hand, having no semantic intuitions of any kind, FOX typically has a hard time with ambiguous data, especially phrases whose structural attachment cannot be inferred from the information provided by the lexicon.
"I am leaving" (... said by a tree in spring)
An important (if frustrating) insight accruing from computational language analysis is the extent to which natural language is permeated by ambiguities which are effortlessly [End of p. 104] resolved by humans, and almost impossible to handle by a program. Given a textual or situational context, a human will immediately know whether the word "seal" in "Look at that seal!" refers to an animal or an authentication device; indeed, human disambiguation is so spontaneous that usually we have no conscious awareness of ambiguity at all. Although the FOX parser is notified of the two meanings of "seal" via its lexicon, it will ignore the resultant ambiguity because it does not affect the sentence's syntactic structure. For the same reason, FOX will also ignore the intuitive difference between "he was seen by the policeman" and "he was seen by the railroad tracks", although it is conceivable that the lexicon could advise the program of a "selection restriction" to the effect that seeing requires an animate agent. Things are different for ambiguous sentences like "Time flies!" (where it is not certain whether this is a command to observe the behavior of flies, or a philosophical remark), "Visiting parents can be boring" (where we do not know who is visiting whom), and "we saw the boy with the telescope" (where one cannot be sure who has the telescope). These are stock examples of structural ambiguity, which a parser should be able to report and represent as different trees. Indeed, FOX will backtrack through the possibilities inherent in "Time flies!". For "Visiting parents ...", it succeeds in identifying "visiting parents" as a subject, but fails to capture that "parents" could also be an object. Like most parsers, FOX is overtaxed by "We saw the boy ...", and the problematic prepositional phrase is simply left dangling.
Program (in)flexibility
Although GB Theory rightly prides itself on the "explanatory adequacy" of its analyses, it restricts itself to a relatively small set of what is optimistically called "core areas" of language. This essentialism unfortunately means that not only a lot of exceptional and variant data, but also many common linguistic phenomena are not (yet) fully accounted for. In point of fact, GB theory itself is in a constant process of expansion and development often characterized by sudden and radical changes in direction. While simple changes in nomenclature (such as the removal of the "S" for "sentence" node) are easily implemented, more radical reorientations like the introduction of additional types of phrases (such as DP, TP, and AgrP) require [End of p. 105] extensive recoding. FOX is not flexible in such matters; being a prototype program, it is largely undocumented and contains a good measure of quick and dirty code. But since it is also modular, short, and based on a very transparent data structure -- "treestrings" -- minor changes and extensions can he incorporated reasonably quickly. Ideally, of course, no coding should he necessary at all. Theoretically, a linguist should simply be able to specify or modify the rules, principles, and parameters of grammar using some suitable, probably declarative, format. Interpreting these specifications, a program should be able to handle any grammar, which means, given a suitable lexicon, any language. FOX is of no use at all in this respect; but at least it helps us speculate about the way things should be.
Beyond textbook cases
Both the data restrictions and the admitted provisionality of GB Theory are, of course, inherited by the FOX parser and limit its practical use. In fact, in its present state, FOX can only handle a small corpus of textbook sentences. It is a model for illustrating parsing strategies which mimick human recognition, for devising the format and extent of lexical entries, and for exploring disambiguation strategies; but that is all.
However, to pursue a speculative tack for a moment, if FOX were not so reductive, an important area of application would be in the field of corpus linguistics, a discipline which focuses on the exploration and exploitation of large textual data bases [6]. Suppose a robust and versatile parser indeed manages to go through a corpus, saving and indexing its trees as it goes along. It is then conceivable that word searches could be augmented by specifications of structural conditions. For instance, one would wish to be able to launch queries such as "Table all objects of the verb see", "List all clauses containing a temporal prepositional phrase", "Collect at least 20 three-word nominal compounds", even "Find everything that Mary is said to benefit from" - and in the latter case the data base program would be expected to highlight "the book" in "We gave the book to Mary" as well as "a flat" in "Mary was offered a flat". Naturally, such a project also involves designing a very sophisticated query interface [7]. [End of p. 106]
Grafting trees
Let us return to the discussion of the problem posed by "we saw the boy with the telescope". As was indicated above, the best FOX can do is to produce the incomplete analysis presented in Fig. 1. Actually, the screenshot shows FOX's analysis after it has been grabbed by the second program, TreeCad. TreeCad, at this stage, is idling, waiting for an interactive command to be clicked on its buttons menu. In order to assess the various PP-adjunctions permitted under a GB regime, one would probably pick "adj" (adjoin) and then click likely target nodes. There are at least three potential candidates: the Nbar associated with "boy", the Vbar, and the Ibar. In each case, TreeCad will generate proper X-bar adjunctions, allowing a systematic exploration of the respective consequences.
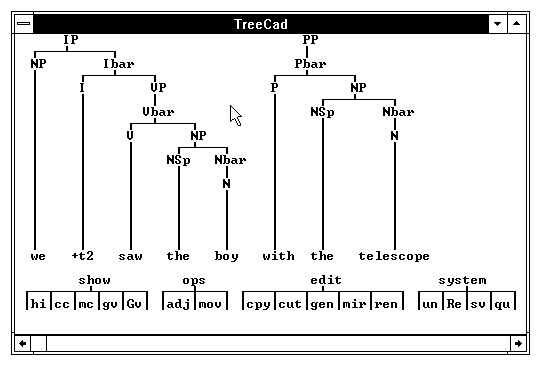
Fig. 1. Exploring PP-attachment in TreeCad
One of the first steps towards transcending purely syntactic structure is to make a program aware of referential restrictions, or "binding principles", as they are called in GB Theory. Thus, even though we are still a long way from implementing a meaning representation of a sentence like "John's brother invited himself", at least a program can be taught to know (and, if necessary act on that information) that [End of p. 107] "himself" must refer to "John's brother", but not to John, and not to anyone else. Similarly, given the sentence "John invited him", there are specific criteria which determine that "him" in this case must be "free", i.e., cannot refer to John. In GB Theory, binding principles are defined as conditions on "government" relations obtaining in a tree. In order to demonstrate that government can be implemented, TreeCad offers the two buttons "gv" and "Gv", one for identifying governors, the other for finding governees. The program picks out the relevant subtrees and nodes by highlighting.
Syntactic translation
TreeCad can also be used to explore relationships across languages, a particular strong point of GB Theory. For instance, given the syntax tree of "Paul will buy the book tomorrow", one might ask which operations are necessary to derive the syntax tree of the German translation, "Paul wird morgen das Buch kaufen". The answer happens to be deceptively simple, in this case, because it can be done in just three "mirroring" operations. Of course, this barely scratches the surface of machine translation. Yet TreeCad can serve to illustrate a level of computational analysis which is pretty close to the present state of expert knowledge, even makes a guess at the direction of possible future inquiry.
Classroom use
In addition to being a tree drawing program and a research instrument, TreeCad can be an effective tool in the classroom. The vision here is that a Linguistics 101 instructor connects his/her portable to an overhead color LCD and clicks a friendly TreeCad icon under Windows. S/he can now conduct an interactive guided tour of current issues in syntactic theory. From a corpus file s/he displays a standard X-bar tree, explaining the roles and characteristics of specifiers, heads, complements and adjuncts. S/he demonstrates that all X-bar structures can be generated from a small set of rewrite rules, some universal, some language-specific. S/he may generate an abstract X-bar tree and ask the students to supply suitable terminals. S/he may display several subtrees and explore possible ways of combining them. Introducing the concept of government, s/he might point the mouse [End of p. 108] arrow to a node and ask, If this were a governor, which nodes would be governees? (Click: TreeCad hilights the governees.) For added flexibility, TreeCad can copy, cut, mirror and rename structures, execute Chomsky-adjunctions and movement transformations as well as undo or redo a sequence of steps.
Best of all, perhaps, the program, including the uncommented source, can be passed on to anyone who is interested, at no cost at all [8].
References
1. Icon is available from many anonymous FTP servers, or from The Icon Project, Dept. of Computer Science, The University of Arizona, Tucson AZ 85721. The primary reference text is [2]. See [8] for more details.
2. Ralph E. Griswold and Madge T. Griswold, The Icon Programming Language, Second Edition, Englewood Cliffs: Prentice Hall, 1990; see the discussion of tree representations in chapters 14 and 15.
3. See Terry Winograd, Language as a cognitive process, Vol. I: Syntax, Reading, Mass.: Addison-Wesley, 1983, for a general survey of various aproaches to parsing; for a discussion of recent developments see Uwe Reyle and Christian Rohrer, eds., Natural Language Parsing and Linguistic Theories, Dordrecht and Boston: Reidel, 1988; Hans-Peter Kolb, "Monotonicity and Locality: Problems of Principle Based Parsing", Zeitschrift fuer Sprachwissenschaft 10:2 (1992), 161-190.
4. Marvin Minsky, "A Framework for Representing Knowledge", Frame Conceptions and Text Understanding, ed. Dieter Metzing, Berlin: de Gruyter, 1979, 1-25.
5. The most accessible introductions to GB Theory are Liliane Haegeman, Introduction to Government and Binding Theory, Oxford: Blackwell, 1991; Andrew Radford, Transformational Grammar: A First Course, Cambridge: Cambridge U.P., 1988.
6. The two main schools of corpus linguistics are known under the acronyms UCREL (U. of Lancaster, Great Britain) and TOSCA (U. of Nijmegen). See Roger Garside, Geoffrey Leech, and Geoffrey Sampson, eds., The Computational Analysis of English, London and New York: Longman, 1987; Nelleke Oostdijk, Corpus Linguistics and the Automatic Analysis of English, Amsterdam and Atlanta: Rodopi, 1991. See also [7].
7. See Hans van Halteren and Theo van den Heuvel, Linguistic Exploitation of Syntactic Databases, Amsterdam and Atlanta: Rodopi, 1990.
[End of p. 109]
8. For ordering a copy on disk, contact the Icon Project - see ref. [1] - on (602) 621-8448, and ask for Program Library Update #10. Copies can also be downloaded from the University of Arizona's FTP (cs.arizona.edu), or BBS (602) 621-2283; look under /icon/contrib/treefox.lzh. Note that the programs require an ordinary (non-386) MS-DOS version of Icon, 640 K of RAM, a VGA monitor, a hard disk, and a mouse.
Manfred Jahn is an Assistant at the English Department of the University of Cologne, D-50923 Cologne, Germany. In addition to computational language processing, he is currently interested in cognitive narratology and techniques of consciousness representation in narrative texts. He can be contacted by email as ame02@rrz.uni-koeln.DE.
This article is an extended version of a paper called "TREE&FOX: Exploring Natural Language Syntax," which was published in The Icon Newsletter, no. 42, July, 1993.
[10 Sep 2000]